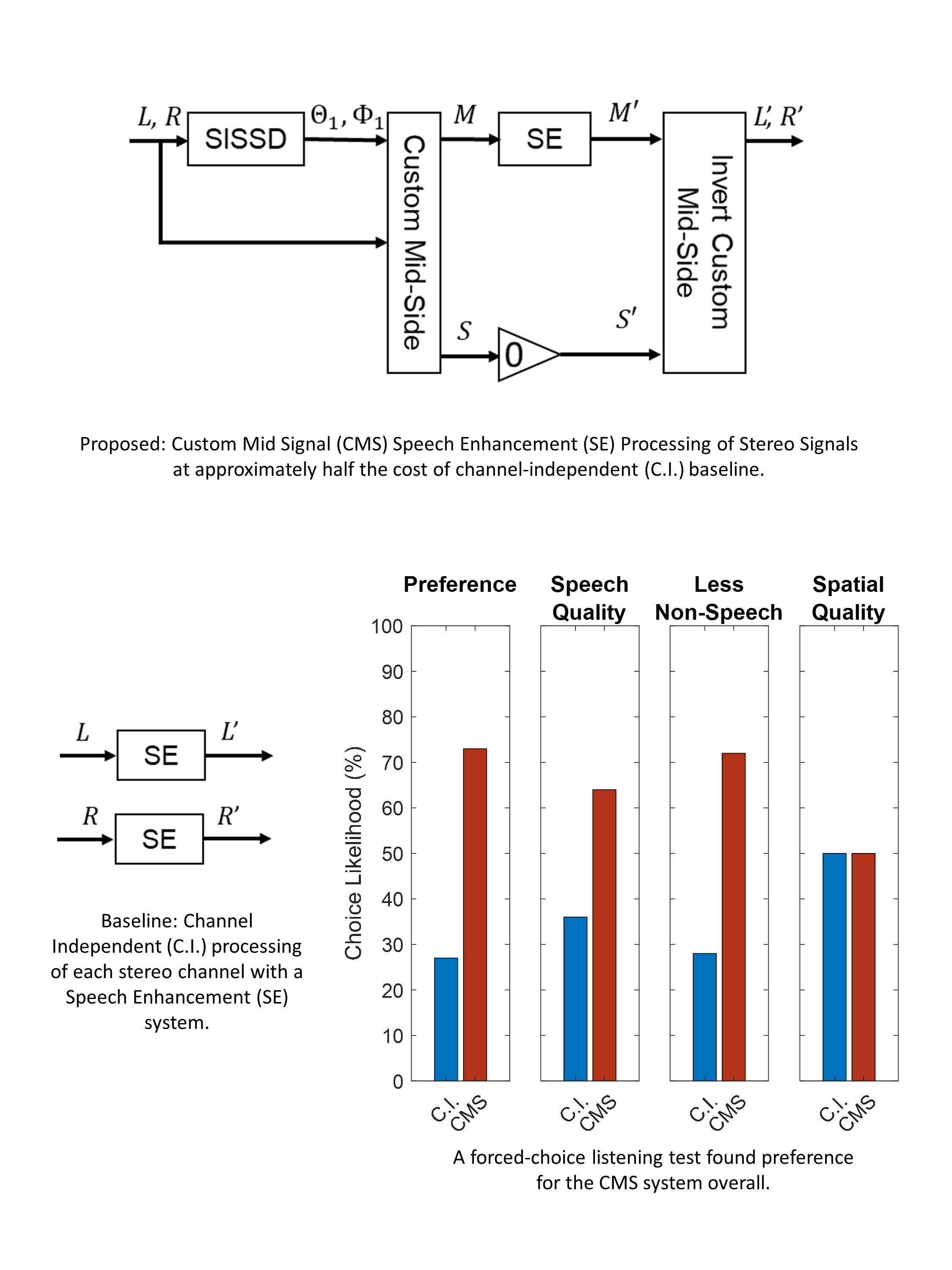
Speech enhancement (SE) systems typically operate on monaural input and are used for applications including voice communications and capture cleanup for user-generated content. Recent advancements and changes in the devices used for these applications are likely to lead to an increase in the amount of two-channel content for the same applications. However, SE systems are typically designed for monaural input; stereo results produced using trivial methods such as channel-independent or mid-side processing may be unsatisfactory, including substantial speech distortions. To address this, the authors propose a system that creates a novel representation of stereo signals called custom mid-side signals (CMSS). CMSS allow benefits of mid-side signals for center-panned speech to be extended to a much larger class of input signals. This, in turn, allows any existing monaural SE system to operate as an efficient stereo system by processing the custom mid signal. This paper describes how the parameters needed for CMSS can be efficiently estimated by a component of the spatio-level--filtering source separation system. Subjective listening using state-of-the-art deep learning--based SE systems on stereo content with various speech mixing styles shows that CMSS processing leads to improved speech quality at approximately half the cost of channel-independent processing.

Open
Access
https://www.aes.org/e-lib/browse.cfm?elib=22148
Download Now (579 KB)
This paper is Open Access which means you can download it for free.
Learn more about the AES E-Library
Start a discussion about this paper!
