Bulk download: Download Zip archive of all papers from this Journal issue

The spatial speech reproduction capabilities of a KEMAR mouth simulator, a loudspeaker, the piston on the sphere model, and a circular harmonic fitting are evaluated in the near-field. The speech directivity of 24 human subjects, both male and female, is measured using a semicircular microphone array with a radius of 36.5 cm in the horizontal plane. Impulse responses are captured for the two devices, and filters are generated for the two numerical models to emulate their directional effect on speech reproduction. The four repeatable speech sources are evaluated through comparison to the recorded human speech both objectively, through directivity pattern and spectral magnitude differences, and subjectively, through a listening test on perceived coloration. Results show that the repeatable sources perform relatively well under the metric of directivity, but irregularities in their directivity patterns introduce audible coloration for off-axis directions.
Click to purchase paper as a non-member or login as an AES member. If your company or school subscribes to the E-Library then switch to the institutional version. If you are not an AES member and would like to subscribe to the E-Library then Join the AES!
This paper costs $33 for non-members and is free for AES members and E-Library subscribers.
Start a discussion about this report!
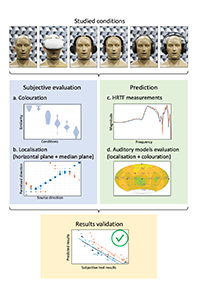
Acoustically transparent head-worn devices are a key component of auditory augmented reality systems, in which both real and virtual sound sources are presented to a listener simultaneously. Head-worn devices can exhibit high transparency simply through their physical design but in practice will always obstruct the sound field to some extent. In this study, a method for predicting the perceptual transparency of head-worn devices is presented using numerical analysis of device measurements, testing both coloration and localization in the horizontal and median plane. Firstly, listening experiments are conducted to assess perceived coloration and localization impairments. Secondly, head-related transfer functions of a dummy head wearing the head-worn devices are measured, and auditory models are used to numerically quantify the introduced perceptual effects. The results show that the tested auditory models are capable of predicting perceptual transparency and are therefore robust in applications that they were not initially designed for.

Open
Access
Download Now (1.0 MB)
This paper is Open Access which means you can download it for free.
Start a discussion about this paper!
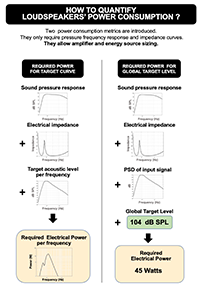
Power performance is often overlooked during speaker system design. With the rise of autonomous systems and the necessity of reducing global energy waste, it has become important to be able to compare and predict the power consumption of loudspeakers. The paper reviews the existing metrics---such as sensitivity and efficiency---extends them, and suggests new ones. Two new metrics that characterize power performance are introduced, which can take the power spectrum density of program material into account in order to adapt to real-life circumstances. They can be easily derived from impedance and frequency response measurements with simple maths and can be specified on loudspeaker datasheets. Used together, they allow performance comparison, power optimization, and energy source sizing. For each, benefits and limits are discussed, and a summary table allows a comparison of each metric characteristic.
Click to purchase paper as a non-member or login as an AES member. If your company or school subscribes to the E-Library then switch to the institutional version. If you are not an AES member and would like to subscribe to the E-Library then Join the AES!
This paper costs $33 for non-members and is free for AES members and E-Library subscribers.
Start a discussion about this paper!
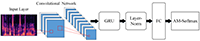
To improve the recognition rate of the speaker recognition system, a model scheme combined with the Additive Margin--Softmax loss function is proposed from the perspective of model differentiation and based on the fusion of Convolutional Neural Network and Gated Recurrent Unit, which not only reduces the distance of similar sample features and increases the distance among different types of sample features simultaneously but also uses layer normalization to constrain the distribution of high-dimensional features. In order to address the problem of poor robustness of the speaker recognition system in real scenes, the SpecAugment data enhancement method is proposed to train the speaker model to combat external environmental interference. Based on the experimental data, the speech recognition performance of the proposed and traditional methods is analyzed. The experimental results show that, compared with other models, the equal error rate based on the Additive Margin--Convolutional Neural Network--Gated Recurrent Unit method is 4.48%, and the recognition rate is 99.18%. Adding layer normalization to the training model can improve the training speed to a certain extent, and the speaker model has better robustness.
Click to purchase paper as a non-member or login as an AES member. If your company or school subscribes to the E-Library then switch to the institutional version. If you are not an AES member and would like to subscribe to the E-Library then Join the AES!
This paper costs $33 for non-members and is free for AES members and E-Library subscribers.
Start a discussion about this paper!

This paper presents a systematic review of semantic music production, including a meta-analysis of three studies into how individuals use words to describe audio effects within music production. Each study followed different methodologies and stimuli. The SAFE project created audio effect plug-ins that allowed users to report suitable words to describe the perceived result. SocialFX crowdsourced a large data set of how non-professionals described the change that resulted from an effect applied to an audio sample. The Mix Evaluation Data Set performed a series of controlled studies in which students used natural language to comment extensively on the content of different mixes of the same groups of songs. The data sets provided 40,411 audio examples and 7,221 unique word descriptors from 1,646 participants. Analysis showed strong correlations between various audio features, effect parameter settings, and semantic descriptors. Meta-analysis not only revealed consistent use of descriptors among the data sets but also showed key differences that likely resulted from the different participant groups and tasks. To the authors' knowledge, this represents the first meta-study and the largest-ever analysis of music production semantics.
Open
Access
Download Now (972 KB)
This paper is Open Access which means you can download it for free.
Start a discussion about this reviewPaper!
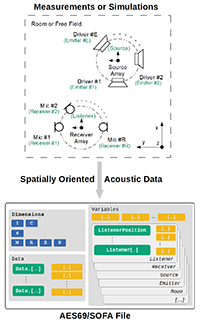
Spatially oriented acoustic data can range from a simple set of impulse responses, such as head-related transfer functions, to a large set of multiple-input multiple-output spatial room impulse responses obtained in complex measurements with a microphone array excited by a loudspeaker array at various conditions. The spatially oriented format for acoustics (SOFA), which was standardized by AES Standard 69, provides a format to store and share such data. SOFA takes into account geometric representations of many acoustic scenarios, data compression, network transfer, and a link to complex room geometries and aims at simplifying the development of interfaces for many programming languages. With the recent advancement of SOFA, the format offers a new continuous-direction representation of data by means of spherical harmonics and novel conventions representing many measurement scenarios, such as source directivity and multiple-input multiple-output spatial room impulse responses. This article reviews SOFA by first providing an introduction to SOFA and then describing examples that demonstrate the most recent features of SOFA 2.1 (AES Standard 69-2022).
Open
Access
Download Now (957 KB)
This paper is Open Access which means you can download it for free.
Start a discussion about this reviewPaper!

Helmholtz resonators are frequently used in audio devices to tune the frequency responses for better performance and listening experience. One of the key challenges in designing this type of Helmholtz resonator is the achievement of appropriate damping without using damping materials. The utilization of nonlinear acoustic damping generated by the airflow separation in Helmholtz resonators is an effective method to address this issue. In this study, loudspeaker systems coupled with Helmholtz resonators were modeled based on the equivalent circuit method (ECM), and the nonlinear damping effect of Helmholtz resonators is considered. The frequency responses of the loudspeaker systems are analyzed using the ECM model and validated experimentally. The influence of nonlinear acoustic damping is investigated. Based on the ECM model, an effective method to tune the acoustic damping of Helmholtz resonators is proposed.
Click to purchase paper as a non-member or login as an AES member. If your company or school subscribes to the E-Library then switch to the institutional version. If you are not an AES member and would like to subscribe to the E-Library then Join the AES!
This paper costs $33 for non-members and is free for AES members and E-Library subscribers.
Start a discussion about this report!
