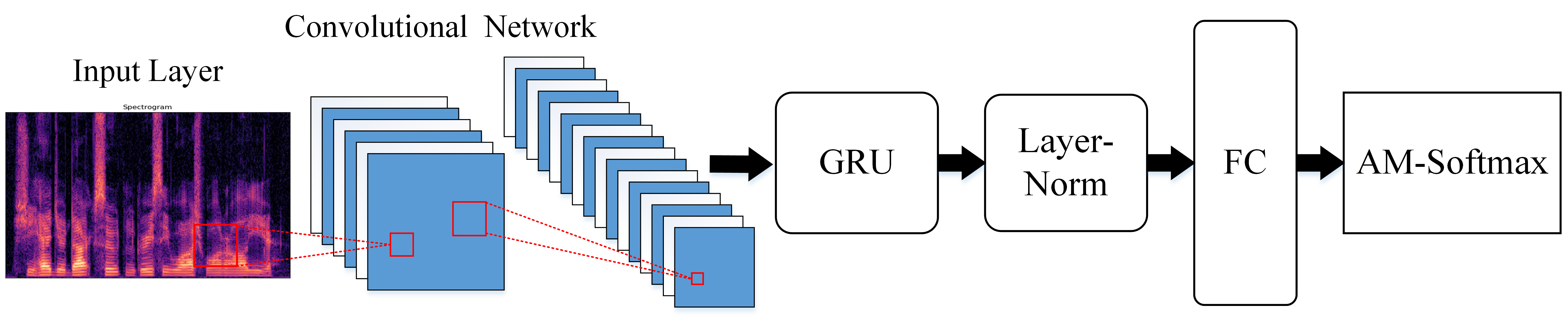
To improve the recognition rate of the speaker recognition system, a model scheme combined with the Additive Margin--Softmax loss function is proposed from the perspective of model differentiation and based on the fusion of Convolutional Neural Network and Gated Recurrent Unit, which not only reduces the distance of similar sample features and increases the distance among different types of sample features simultaneously but also uses layer normalization to constrain the distribution of high-dimensional features. In order to address the problem of poor robustness of the speaker recognition system in real scenes, the SpecAugment data enhancement method is proposed to train the speaker model to combat external environmental interference. Based on the experimental data, the speech recognition performance of the proposed and traditional methods is analyzed. The experimental results show that, compared with other models, the equal error rate based on the Additive Margin--Convolutional Neural Network--Gated Recurrent Unit method is 4.48%, and the recognition rate is 99.18%. Adding layer normalization to the training model can improve the training speed to a certain extent, and the speaker model has better robustness.
https://www.aes.org/e-lib/browse.cfm?elib=21827
Click to purchase paper as a non-member or login as an AES member. If your company or school subscribes to the E-Library then switch to the institutional version. If you are not an AES member and would like to subscribe to the E-Library then Join the AES!
This paper costs $33 for non-members and is free for AES members and E-Library subscribers.
Learn more about the AES E-Library
Start a discussion about this paper!
