Heyser Memorial Lecture
AES 114th Convention
RAI Conference and Exhibition Center, Amsterdam, The Netherlands
Sunday, March 23, 18:10 h
COMMUNICATION ACOUSTICS: AUDIO GOES COGNITIVE!
by Jens Blauert, Institute of Communication Acoustics, Ruhr-Universität Bochum, Germany
Abstract
 I will discuss how the specific branch of acoustics relating to information technologies has experienced a dramatic evolution during the last 30 years. With input from signal processing, psychoacoustics, and computer science, among other fields, communication acoustics has evolved from audio engineering, which grew from a symbiosis of electrical engineering and acoustics.
I will discuss how the specific branch of acoustics relating to information technologies has experienced a dramatic evolution during the last 30 years. With input from signal processing, psychoacoustics, and computer science, among other fields, communication acoustics has evolved from audio engineering, which grew from a symbiosis of electrical engineering and acoustics.
Taking computational auditory scene analysis (CASA) as an example, I will show that a major goal in this field is the development of algorithms to extract parametric representations of real auditory scenes. To achieve such results, audio signal processing, symbolic processing, and content processing have become significantly important. Increasingly knowledge-based CASA systems are the result. We have already developed CASA systems that mimic and even surpass some human capabilities of analyzing and recognizing auditory scenes.
Using synthesis tools (such as virtual-reality generators) to manufacture auditory scenes, we can provide an astonishing amount of perceptual plausibility, presence, and immersion. These synthesis tools are multi-modal: capable of simulating, in addition to sound, the senses of touch (also vibration), vision, and even the illusion of movement. The synthesis systems are parameter controlled and often interactive.
Cognitive and multi-modal phenomena have to be considered in both audio analysis and synthesis. Consequently, future audio systems will often contain knowledge-based and multi-modal components. And we will increasingly see audio systems being embedded in more complex systems. This technological trend will coin the future of communication acoustics, and audio engineering as a subset. We must address the urgent problem that many audio engineers are not yet ready to meet the challenge of designing knowledge-based and multi-modal systems.
Summary of Lecture
Communication Acoustics: Audio Goes Cognitive
(Abstract of the 8th Richard C. Heyser Memorial Lecture, Amsterdam, March 2003)
Jens Blauert
Ruhr-Universität Bochum, D-44780 Bochum, Germany
Instrumental analysis and synthesis of auditory scenes are a major current issue in Communication Acoustics, particularly coding of scenes and generation of scenes from code. As an introduction to these topics we start with the consideration of a class of systems which are typical for audio engineering, namely, audio-transmission systems. These systems have the following essential components: one or more microphones, means to transmit, store and process audio signals, and loudspeakers or headphones at the play-back end. With authentic transmission in mind, so-called binaural systems are a good choice, i. e. systems which use artificial heads as a front end (Fig. 1).
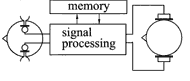
Fig. 1 Schematic of an audio-transmission system
As Fig. 2 shows, such systems can be separated into two parts, the left panel representing the analysis side and the right one the synthesis side. As to the analysis side, this can be interpreted as a system where the listener of Fig. 1 has been replaced by a signal-processing component which, in a way, mimics the perceptive and mental capabilities of a listener – depending on the specific purpose of the computational analysis. In the synthesis system, auditory scenes are generated from input information which, in a complete transmission system, would originate from the analysis part - for example, information gained by computer algorithms based on perceptive and mental processes. In communication acoustics the analysis side is often termed "computational auditory scene analysis (CASA)", while the synthesis side is called "auditory virtual-reality generation (AVR)".
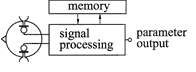

Fig. 2 Schematic of systems for computational analysis (left)
and computational synthesis of auditory scenes (right)
Computational Auditory Scene Analysis (CASA)
There is pronounced technological demand for auditory scene analysis. Important application areas are: systems for the identification and localization of sound sources - especially in acoustically adverse environments, such as multi-source, noisy or reverberant situations - e.g., for acoustically-based surveillance and/or navigation. Further, systems to separate and “decolor” concurrent sound sources (so-called cocktail-party processors) that are, for instance, needed as front-ends for hearing aids or robust speech recognizers. Also, for the modeling of auditory recognition and assessment tasks, it is often advisable or even indispensable to start with a scene analysis, for example, in systems for analysis in architectural acoustics or in systems for quality assessment of speech and product sounds. Also, in this context, so-called “content filters” are worth mentioning. These filters gain in relevance with respect to the tasks of automatic archiving and retrieving of audio-visual program material. There, they are used to analyze and code the contents of this material (see the MPEG7 coding as proposed by ISO/IEC).
As far as CASA systems make use of human auditory signal processing as a prototype, their structure follows, as a rule, a schematic as given in Fig 3. The systems are binaural, i. e. have two front ports which take the signals from the left and right ear of a human or a dummy head as an input. Relevant signal-processing stages are as follows: After a moderate band-pass filtering, which simulates the middle ear, the two ear signals are fed into a cochlea model. Here, two things are done: The signals are decomposed into ear-adequate spectral components (so-called critical bands) and than converted into signals which represent the neural activity (spike-density function) as generated by the inner ear. The two cochlea-output signals are then sent to a binaural module which analyzes the interaural arrival time and level differences, i. e. differences between the left- and right-ear signals. This information is later needed to identify individual sound-sources and their lateral positions in space - amongst other features. From this process a 4-dimensional pattern (time, frequency, intensity, lateral position) results, which is called “binaural activity pattern”. Of course, it has to considered too that we can also hear with one ear only (additional monaural modules).
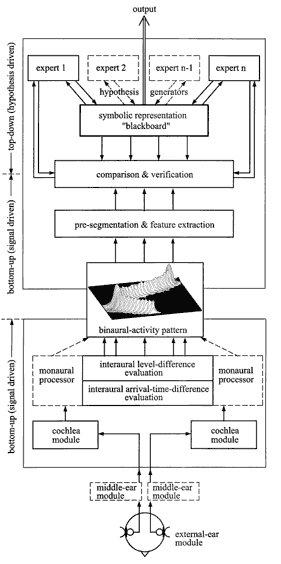
Fig. 3 Architecture for an analysis system for auditory scenes.
A number of tasks within CASA can be performed based on this, so far strictly bottom-up, processing and its resulting binaural activity pattern, e. g., localization and tracking of multiple sound sources in not-too-reverberant scenarios. Also decoloration and separation of concurrent sound sources succeeds quite well under these conditions – sometimes even better than humans can do.
Unfortunately, these algorithms decrease rapidly in performance with reflected sound being added in quantities which are typical for common architectural spaces. It seems that a strictly bottom-up process cannot deal well with these situations – amongst others. For this reason more recent approaches provide modules on top of the binaural activity pattern which work on a top-down basis, i. e. hypothesis-driven, rather than on a bottom-up, signal-driven basis. In this way, it becomes possible to include knowledge-based processing into the structure. Model architectures of such a kind had already proven to be successful in automatic speech recognition.
A possible architecture for the complete system is depicted in the upper part of Fig 3. The binaural activity pattern is input to a grouping and segmentation process which produces an – usually error infected – symbolic representation of it. The symbolic representation is then put on a “black-board module”, where it can be inspected by different knowledge based “expert” modules. The expert modules, then, generate hypotheses with the aim of arriving at plausible interpretations of the activity patterns with the aim of producing a meaningful identification and analysis of the auditory scene. The individual hypotheses are evaluated step by step, eventually modified, and finally accepted or rejected. Each expert module acts on the basis of its specific knowledge. This knowledge can be represented in the form of explicit rules or data bases. Typical knowledge domains involved are, e. g., knowledge of the current position of the sound-recording head, prior knowledge on the scene, cross-modal information (tactile, visual, etc.), knowledge about the sound source and the sound signals radiated by it. Non-auditory sensual information (e.g., visual, tactile, proprioceptive) may also be considered. Once a plausible parametric representation of the auditory scene has been obtained in this way, any further processing and utilization depends on the specific task involved.
Auditory Virtual Reality (AVR) Instrumental synthesis of auditory scenes is currently of even higher relevance than their instrumental analysis – particularly where the listeners can interact with the synthesized scenes. In the following, a number of possible applications are listed as examples, based on projects which the Institute of Communication Acoustics at Bochum has been involved in: auditory displays for pilots of civil aircraft, AVR for the acoustic design and evaluation of space for musical and oral performances, for individual, interactive movie sound, and for teleconferencing. Further, there are virtual sound studios and listening rooms, musical practicing rooms, and systems to generate artificial sound effects, Further applications are: AVR for archiving cultural heritage, for training (e.g. police and fire-fighter training), for rehabilitation purposes (motoric training) and as an interface to the web (internet kiosk). Last but not least, AVR is a preferred tool for research purposes (e. g. psychophysics, behavioral studies). Conclusions Communication Acoustics deals with those aspects of acoustics which relate to the information, communication and control technologies. Modern systems in these areas frequently contain embedded components which deal with the analysis and synthesis of auditory scenes - a genuine field of activity for Communications Acoustics. As Communication Acoustics, among other things, deals with both the acoustic and the auditory domains it is truly interdisciplinary. (Note: A full version of this lecture is being prepared and will form a chapter of a book on Communication Acoustics to be edited by this author and to be published in 2004 by Springer Verlag, Heidelberg, New York.)
- especially so-called spatializers - and the auditory representation in simulators of all kinds of vehicles (e.g., aircraft, passenger cars, trucks, train, motorcycles).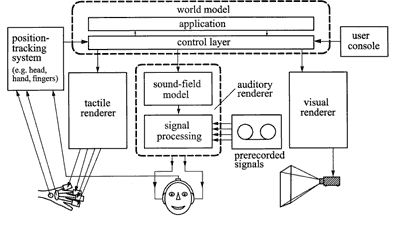
Fig. 4 Schematic of a virtual-reality generator with
auditory, tactile and visual representation
In the following, the architecture of an auditory virtual-reality generator is schematically depicted (Fig. 4). To clarify that AVR is usually a component of multi-modal VR generators, i. e. an embedded system, the figure shows an auditory/tactile/visual generator. The example shows a system where the acoustic signals are presented via headphones. Loudspeaker presentation would be possible, too. Multi-channel loudspeaker reproduction systems as used in consumer electronics (movie theatres, home theatres, TV, CD, DVD, radio) can indeed be seen as a first step towards virtual reality - although they usually lack an important feature of VR, namely, interactivity. The sample system in Fig. 4 contains as its core, a “world model”. This system component, among other things, contains descriptions of all objects which are to exist in the VR. In a layer inside the world model, rules are listed which regulate the interaction of the objects with respect to the specific applications intended. Then, a central-control layer collects the reactions of the subjects which use the VR system interactively and prompts the system to execute appropriate responses. In other words, the world model is a part of the system which is essentially knowledge based, i.e. contains explicit knowledge in the form of data-banks and rules.
In the system shown, head, hand, and finger positions of the subject are continuously monitored. The head positions are of relevance, as the signals, being presented via the headphone, have to be adapted constantly for the subject to perceive a spatial perspective which stays spatially still when the head is moving about. By moving hands and fingers the subjects can influence the virtual reality. Those system components that generate the signals which are finally presented to the subjects via actors (headphones for the auditory modality) are called "renderers". The most important component of the auditory renderer is the sound-field model. This is a module which creates a set of binaural impulse responses based on the geometric data of the virtual space, plus the absorption characteristics of all walls and geometrical objects in the space, plus the directional characteristics of both sound source and receiver. The characteristics of the receiver are given by the subject’s head-related transfer functions (HRTFs). These HRTFs must be measured individually on the subjects to achieve best possible performance. The binaural impulse responses contain all information on the auditory environment, are then convolved with electronically or pre-recorded signals such as speech or music. These signals should be acoustically ”dry”, i.e. not contain a-priori room information. The product of the convolution process is then fed into the headphones.
In many applications of virtual reality it is aimed at exposing the subjects to a virtual situation such that they feel perceptively “present” in it. This is especially important whenever scenarios are to be created in which the subjects are supposed to act intuitively – as they would do in a respective real environment. Human/system interfaces which base on the principle of virtual reality have the potential of simplifying human-system interaction considerably. Think of tele-operation, design or dialog systems in this context – also of computer games. The efforts involved in creating perceptual presence is task specific and dependent on the particular user requirements. For example, for vehicle simulators the perceptual requirements are far less stringent than for virtual control rooms for sound engineers. Generally, the virtual environment must appear sufficiently “plausible” to the listener to provide presence. As soon as interaction is at stake – and this is the rule with generators for plausible virtual-reality – real-time signal processing becomes indispensable. The system reaction must happen within a perceptually-plausible time span (for the auditory representation within roughly 50 ms). Further, the refresh rate for the generated scene must be so frequent that the perceptual scenario neither jolts nor flickers. To this end the refresh rate has to be above 30 times per second for moderately moving objects. For objects moving fast, Doppler shifts may have to be taken into consideration and modeled. To develop a reasonable fast generator for plausible VR, the developer, needs detailed knowledge on human sensory perception, since it has to be decided at every instant which attributes of the signals are perceptually relevant and, thus, have to be presented accurately and instantly. Less relevant attributes can be calculated later or even be omitted.
Modern speech technology offers components which can be integrated into virtual reality. Examples are: systems for instrumental speech synthesis and recognition. By utilization of these, human-system interaction can be performed via voice signals, thus incorporating human-machine speech dialogs into the systems. In this context, it is worthwhile mentioning that the perception of one’s own voice in virtual realities is an important issue. Through careful analysis and simulation of the sound propagation through the air and through the skull, this task could recently be mastered. Since virtual worlds are artificial, namely, generated by computers, they rest on parametric representations of scenes. Then the parameters which represent a scenario, can be transmitted across time and space with telecommunication technologies. There exist description languages already which allow virtual worlds to be defined and specified in a formal, parametric way. The representation includes semantic (content) aspects. MPEG7 coding, as mentioned above, plays a role in this regard.
With the use of parametric coding it becomes possible that users, which actually reside in different locations, displace themselves perceptually into a common virtual room, where they may confer together (tele-conferencing) or even jointly exercise a mechanical task (tele-operation). Further, one may enter a virtual environment to inspect it or objects in it (e.g., virtual museum, virtual tourism). As entrance to virtual spaces can be provided via the internet, manifold applications can be imagined. VRs can further be superimposed on real realities (augmented reality) to assist navigation or provide other on-line support. Further, virtual realities are a very useful tool for scientific research. This is mainly due to the fact that they allow for flexible and economic presentation of complex experimental scenarios. Scenarios can be modified and changes can be performed without any physical effort. Research in areas like psychophysics, psychology, usability, product-sound design and assessment is about to take advantage of this possibility.
With computational auditory scene analysis (CASA) taken as one example, it was shown that a major research aim in the field is the development of algorithms which analyze real scenarios in order to extract a parametric representation. Some human capabilities in analysis and recognition can already be mimicked or even surpassed. To achieve this, in addition to audio-signal processing, symbolic processing and content processing are needed. Especially in modern speech technology this line of thinking can clearly be observed. As to the synthesis of auditory scenarios (AVR), it becomes evident that the virtual-realty generators become more and more multi-modal and knowledge based. In a close alliance with the auditory modality, tactile (incl. vibration), visual and proprioceptive information is presented. The synthesis is parameter controlled and interactive in a majority of cases. Also in this context, speech technology has taken a leading role (e.g., in the form of spoken-dialog systems).
It is obvious that advanced systems in information, communication and control technologies become increasingly knowledge-based and multi-modal., i.e. the systems contain explicit knowledge, consider contents and interact on a cognitive level. This development has now reached Communication Acoustics as well: "Audio Goes Cognitive". The good news about this is, that Communication Acoustics thus faces an extremely interesting challenge, as cognition has to do with the mental capabilities of human beings - and humans have always been the most interesting object of human research. The bad new is that, as a rule, audio engineers and acousticians are not yet sufficiently educated to meet this new challenge.
